

La scalabilité est le mot-clé de la décennie. Et c’est tant mieux : rarement un concept aura autant révolutionné le monde de l’informatique — et par ricochet, celui de l’entrepreneuriat.
Mais entre discours marketing fumeux et fantasmes technophiles, il est un point que l’on oublie (bien) trop souvent : être scalable est un défi technique et organisationnel majeur. Et que beaucoup confondent croissance et scalabilité.
Alors, on vous a préparé une explication ultra-complète, avec les 1500 mots les plus importants que vous lirez cette semaine.
Sommaire
- Définir le concept, son histoire et ses nuances.
- Comprendre pourquoi elle est essentielle.
- Explorer les différents types de scalabilité et leurs usages.
- Identifier les pièges à éviter.
- Découvrir une roadmap pour atteindre la scalabilité.
- Étudier des exemples concrets à travers le monde.
On se retrouve dans les commentaires ↓
La scalabilité : comprendre un concept clé de l'informatique moderne
Définition : au-delà du jargon, qu'est-ce que la scalabilité, concrètement ?
Il fallait bien l’ère du cloud et des pitchs de start-up pour voir surgir la "scalabilité" sur toutes les lèvres, comme si ce mot valait promesse d’immortalité logicielle. Définir la scalabilité, c’est accepter de regarder au-delà de la poudre aux yeux marketing : il ne s’agit pas, contrairement à ce que l’on aimerait croire dans des boardrooms trop parfumés, d’une capacité magique à grossir sans douleur ou sans coût.
En informatique, la scalabilité désigne très froidement la capacité d’un système, d’une application ou d’une architecture à absorber une augmentation (ou une baisse) du volume de travail, tout en maintenant un niveau de performance acceptable. On parle là d’aptitude à "monter en charge", mais aussi – nuance souvent oubliée – à "descendre" sans se disloquer quand la fête est finie.
« La scalabilité est le mirage qui promet le confort avec la tempête, puis exige de vous l’endurance d’un marathonien. »
Il est tentant (et certains cabinets ne s’en privent pas) de vendre la scalabilité comme une panacée technologique et managériale. Pourtant, soyons honnêtes : derrière ce terme se cache un défi technique et organisationnel d’une rare violence. On ne scale pas par décret PowerPoint : il faut réarchitecturer, anticiper les goulets d’étranglement et aligner équipes et process. L'histoire regorge d’exemples où le "scalable" autoproclamé a explosé au premier pic réel – Airbnb lors de ses premiers gros événements n’a pas été bâti sur du vent : il y a eu crash… et refonte.
Ce que beaucoup feignent encore d’ignorer : la scalabilité n’est pas synonyme de croissance. La croissance peut très bien être chaotique ou inefficace — un ERP incapable d’absorber plus de commandes n’a rien gagné à passer de 1000 à 10 000 utilisateurs si son coût explose ou si ses délais deviennent rédhibitoires.
L'origine du terme : quand l'informatique a décidé de jouer au plus gros.
Si l’on gratte l’histoire (et qui prend encore ce temps aujourd’hui ?), le terme scalabilité vient tout droit de l’anglais "scale", signifiant échelle. Il s’est faufilé dans le vocabulaire technique lors des premières heures de l’informatique moderne, époque bénie où Sun Enterprise et consorts affichaient fièrement leur capacité à grossir selon les besoins clients – quitte à facturer chaque brique supplémentaire au prix du caviar iranien.
C’est avec l’apparition des systèmes distribués et la montée en flèche des réseaux que le terme s’est vraiment démocratisé. Les géants technos ont vite compris l’intérêt commercial du mot : Amazon vantant son cloud "hautement scalable", Google érigeant la montée en charge comme dogme fondateur… Ce n’est donc pas une coïncidence si chaque framework open source depuis 2010 affiche désormais un badge "scalable by design" – une auto-proclamation rarement vérifiée in situ !
On notera aussi que l’usage professionnel s’est depuis étendu jusqu’à contaminer le discours entrepreneurial généraliste : parler de modèle économique scalable équivaut désormais à rassurer son investisseur sur sa capacité hypothétique à encaisser le succès — même si ladite capacité n’a jamais été éprouvée autrement qu’en projection Excel fantaisiste.
Anecdote révélatrice : lors du lancement européen d’un service autrefois confidentiel (restons charitables), j’ai vu une équipe entière célébrer avoir rendu leur back-end "scalable"... alors qu’il plantait dès 200 connexions simultanées. Manifestement, personne ne savait ce que signifiait vraiment scaler autre chose qu’un argumentaire commercial !
Synonymes et nuances : extensibilité, échelonnabilité, quelles différences ?
La France adore ses synonymes raffinés (pour masquer les absurdités conceptuelles ?). On parle donc aussi volontiers d’extensibilité ou d’échelonnabilité pour désigner cette aptitude à évoluer sous contrainte croissante. Dans le monde anglo-saxon, scalability reste roi — mais chez nous, on aime nuancer :
- Scalabilité, c’est la possibilité pure et simple d’agrandir (ou réduire) un système en fonction des besoins ;
- Extensibilité, davantage associée à la faculté d’étendre fonctionnellement une solution – ajouter des modules sans tout casser ;
- Échelonnabilité, moins usité en français moderne, correspond historiquement à cette idée (notamment dans les médias broadcast) de pouvoir répartir ou échelonner charges et ressources.
Pour être franc : dans 95% des conversations techniques ou business actuelles, ces termes sont utilisés indifféremment — preuve que peu veulent s’encombrer avec des subtilités pratiques quand il s’agit surtout de vendre… ou rassurer ! Néanmoins, ceux qui architecturent vraiment savent combien ces nuances peuvent coûter cher lorsqu’on découvre après coup qu’on s’est trompé d’approche sous couvert de synonymie paresseuse.
Le mythe du « scalable by design » : une promesse tenue ou une belle formule ?
Ah… le fameux label "scalable by design" ! S’il suffisait d’ajouter cette mention sur un schéma pour garantir qu’un système survivra aux marées montantes… La réalité est insidieusement plus cruelle :
Le scalable by design relève souvent plus du vœu pieux que du contrat solide. Oui, on peut concevoir en théorie pour faciliter les adaptations ultérieures — segmentation logique, découplage fonctionnel etc. Mais affirmer qu’une architecture sera de facto scalable sans effort additionnel relève soit de l’incompétence crasse soit du cynisme commercial bien rodé.
Soyons sérieux : même les designs les mieux pensés finissent par révéler leurs failles face aux usages réels sur le terrain. Toute évolution majeure implique un retravail architectural, une refonte partielle, voire un refactoring douloureux (demandez donc aux équipes historiques d'eBay pourquoi migration rime avec nuits blanches).
Sans vouloir froisser ceux qui vivent encore dans un conte LinkedIn :
- La croissance brute ne garantit rien sinon l’amplification exponentielle des défauts initiaux ;
- Scalabilité = efficacité accrue, pas simple empilement quantitatif (pensez microservices dispersés vs monolithe hypertrophié — tous deux peuvent échouer lamentablement).
Bref… Avant de graver "scalable by design" sur votre roadmap produit ou infrastructurelle :
avouez-le — c’est surtout un slogan destiné à tranquilliser actionnaires & clients naïfs plutôt qu’une assurance tous risques rationnelle.
Pourquoi la scalabilité est-elle le Graal de l'informatique et des entreprises ? L'obsession du 'toujours plus'.
La performance au rendez-vous : quand le système ne flanche pas sous la pression.
Il est presque risible d’observer certains décideurs s’émerveiller devant la « scalabilité », comme si celle-ci procédait d’un miracle technique. La réalité, pourtant, est nettement plus prosaïque : un système scalable garantit une performance stable lorsque la charge explose – ou, soyons exacts, il tente de ne pas s’effondrer piteusement lors d’un pic soudain (pensons à la ruée sur les sites de billetterie en pleine vente de places pour un concert événement… et aux crashs récurrents des plateformes mal dimensionnées).
Dans les architectures dignes de ce nom : l’ajout d’utilisateurs ou l’augmentation des transactions n’entraîne pas une chute vertigineuse de la réactivité. Cette robustesse repose sur des capacités dynamiques : équilibre de charge intelligent, allocation automatique des ressources, découplage des composants critiques…
Quelques exemples évocateurs ? Les plateformes vidéo mondiales qui diffusent sans broncher lors des finales sportives planétaires, ou les infrastructures bancaires modernes capables d’absorber les pointes à Noël et au Black Friday sans transformer chaque paiement en loterie anxiogène pour le client. C’est cette constance qui sépare les systèmes sérieux des bricolages amateurs.
Résumons sans détours : une architecture scalable assure une expérience utilisateur fluide, une disponibilité accrue et une agilité certaine face à l’inattendu.
Résumé – Les principaux bénéfices pour vos systèmes informatiques :
- Performance constante, même lors d’augmentations soudaines du trafic ;
- Haute disponibilité : réduction drastique du risque de panne globale ;
- Flexibilité dans l’allocation des ressources, limitant le gaspillage ;
- Expérience utilisateur préservée, indépendamment du volume.
La croissance sans douleur : passer du petit au géant sans y laisser ses plumes.
Ici réside tout le sel : la scalabilité n’est pas un simple bonus technique, c’est un prérequis existentiel pour toute entreprise – startup comme géant historique – qui espère naviguer sereinement dans la tempête de l’hyper-croissance. On aurait pu rêver mieux que ces pitchs où l’on confond encore être scalable et « avoir beaucoup d’utilisateurs ». Mais avouez-le : soutenir une croissance soutenue exige bien davantage qu’une multiplication naïve des serveurs ou une augmentation budgétaire aveugle.
Prenez le cas du Groupe Le Figaro (pour changer du sempiternel Facebook) : leur succès numérique repose en partie sur des plateformes taillées pour absorber hausses brutales du lectorat sans sacrifier vitesse ni intégrité éditoriale. À l’inverse, combien de startups ont implosé après avoir fait le buzz simplement parce que leur back-end n’a pas suivi ? Combien ont livré une expérience dégradée au pire moment, ruinant toute perspective durable ?
La scalabilité fait ainsi la différence entre ceux qui transforment leur essai… et ceux qui entrent dans la longue file d’attente des déceptions évitables.
L'efficacité économique : faire plus avec, idéalement, moins.
Soyons clairs : investir dans la scalabilité a un coût initial indéniable (matériel adapté, ingénierie complexe, tests intensifs). Mais refuser cet investissement s’apparente à acheter une voiture sans freins en espérant ne jamais descendre une pente. Les entreprises vraiment avisées comprennent que le vrai calcul se joue sur le long terme : un système scalable permet de supporter plus d’utilisateurs sans devoir doubler les effectifs ou multiplier les machines à chaque montée en charge. Il optimise donc les coûts opérationnels au lieu de générer des refontes perpétuelles (et douloureuses) à chaque nouvelle étape clé de croissance source.
À l’opposé, persister dans le non-scalable condamne invariablement à voir exploser les dépenses – maintenance ingérable, perte de clients excédés par la lenteur ou interruptions récurrentes, investissement massif imprévu pour "rattraper" l’échec architectural initial. Un modèle qui fleure bon l’amateurisme assumé...
L'adaptabilité face aux imprévus : parer aux changements de demande, des caprices de marché aux coups de boutoir.
Le propre d’un environnement numérique contemporain ? Son imprévisibilité chronique. Un bon système scalable répond présent dès que surgit un pic inattendu ou qu’une fonctionnalité doit être déployée en urgence (bonjour RGPD). Il absorbe et réalloue ses ressources quasi-instantanément grâce à ses fondations flexibles – cloud computing oblige –, là où son homologue rigide imploserait devant la moindre vaguelette non prévue au planning.
Une anecdote qui vaut son pesant d’ironie : lors d’un lancement produit raté chez un acteur tech moyen-gamme non préparé au bad buzz viral sur Twitter... Il aura suffi d’une nuit pour que tout bascule — bases saturées, interfaces hors-service, réputation carbonisée avant même Noël. Morale ? On ne prédit jamais assez vite sa propre défaite quand on néglige la résilience architecturale !
Ce niveau d’agilité est essentiel pour tous ceux dont le business dépend du numérique — marchés volatiles compris — car retomber sur ses pieds devient alors question de survie pure.
Le poids des contraintes : les systèmes qui résistent à la montée en charge, et ceux qui implosent.
L’histoire fourmille d’exemples frappants où ignorer sciemment la scalabilité a mené droit dans le mur. Que ce soit ce fameux entrepôt dont toute logistique s’effondre faute d’automatisation adaptée (source), ces sites e-commerce KO dès leur première campagne télévisée nationale… Ou encore ces applications mobiles incapables techniquement d’ajouter plus que quelques centaines d’utilisateurs faute de design sérieux (oui oui c’était courant jusqu’en 2015). René J. Chevance aurait souri jaune devant tant d’incompétence méthodologique !
Pour résumer : on ne badine pas avec la montée en charge sous peine de voir son projet relégué très vite au cimetière numérique… La scalabilité n’est ni luxe ni mode passagère mais arme absolue contre l’échec programmé.
Scalabilité verticale vs. horizontale : choisir son arme dans la bataille de la capacité
Scalabilité verticale : renforcer une seule machine
Parlons franchement : la scalabilité verticale – ou "scale up" pour les anglomaniaques du secteur – consiste à renforcer un serveur existant, lui greffer davantage de RAM, gonfler son processeur, multiplier ses baies de stockage… Bref, il s’agit d’injecter toujours plus de muscles à une machine unique, jusqu’à ce que la loi physique (ou le fabricant) dise stop. Simple, intuitif, presque rassurant pour les nostalgiques d’une informatique centralisée : plus besoin de jongler avec des fermes entières de serveurs. On change la bête pour une bête plus grosse – on aurait cru voir un parc de machines évoluant façon Pokémon.
En pratique ? Cette approche a ses avantages : déploiement initial ultra-rapide, gestion centralisée des données (tout reste sur le même nœud), maintenance simplifiée et coût d’entrée relativement limité si l’on reste raisonnable sur la puissance visée. Les administrateurs système aux cheveux grisonnants vous le diront : gérer UN serveur qui grossit est infiniment moins migraineux que synchroniser trente nœuds fébriles.
Mais la plaisanterie a vite ses limites. D’abord parce que le coût des machines haut de gamme grimpe en flèche dès qu’on quitte le mainstream – et il faut être prêt à y laisser quelques budgets formation continue. Ensuite, chaque upgrade rend le point unique de défaillance plus douloureux que jamais : si votre monstre tombe, tout s’arrête net, sans filet. Enfin (et c’est peu dire), cette stratégie bute forcément sur une barrière physique : pas question d’assembler indéfiniment processeurs ou barrettes mémoire… Sauf à croire encore au marketing des constructeurs !
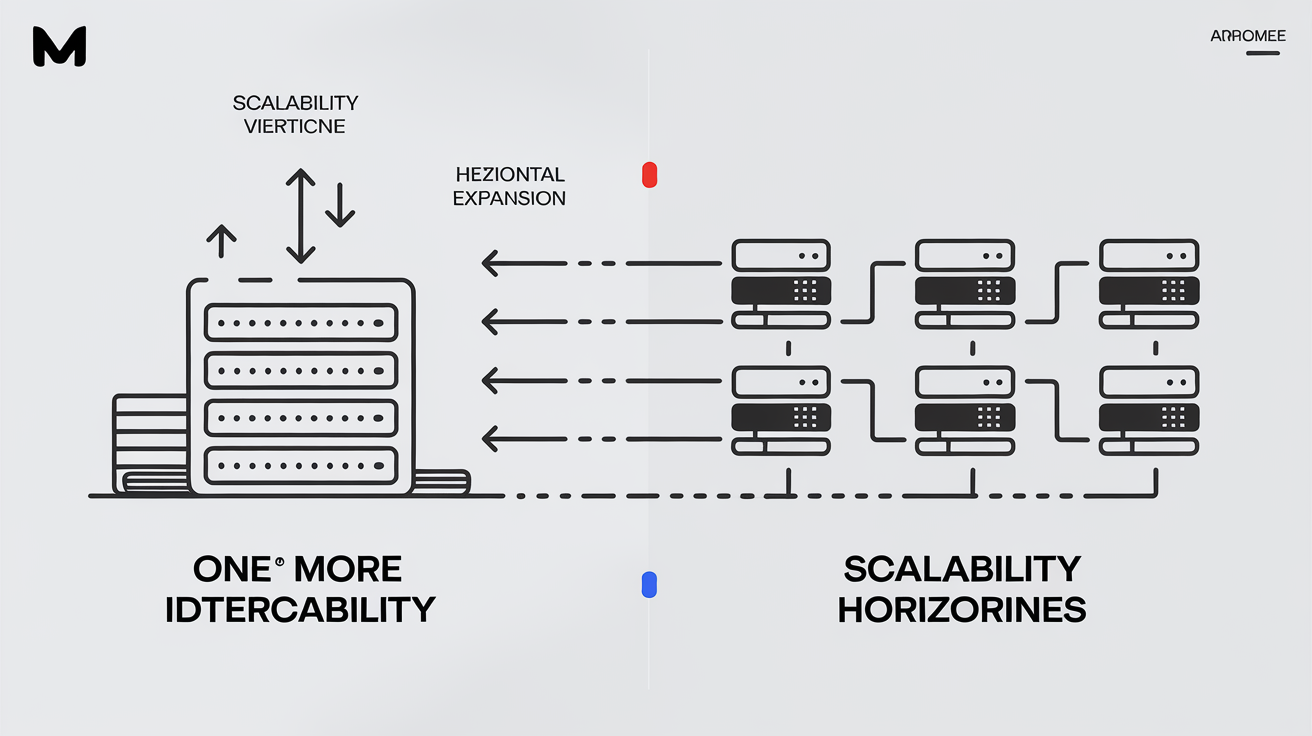
Scalabilité horizontale : multiplier les machines
Changeons radicalement de paradigme avec la scalabilité horizontale : ici, au lieu d’offrir du caviar au même serveur obèse, on préfère aligner plusieurs machines standards en parallèle — on "scale out" en ajoutant des unités identiques mais modestes qui collaborent joyeusement à distribuer la charge.
Le vrai bénéfice saute aux yeux : flexibilité maximale et résilience naturelle aux pannes individuelles (un serveur claque ? Les autres prennent la relève). Cette méthode permet aussi d’ajuster très finement sa capacité en fonction des besoins réels – ajoutez ou retirez des nœuds comme vous modifiez votre playlist Spotify… sauf que cela demande un certain doigté technique.
L’avantage économique n’est pas qu’une légende urbaine : acheter dix machines standards coûte souvent moins cher qu’un mastodonte personnalisé, surtout si l’infrastructure doit croître par paliers successifs (source).
Mais il faut aussi se montrer lucide : orchestrer convenablement un réseau distribué exige un savoir-faire rare et une discipline technique sans faille ; la cohérence des données devient rapidement une épreuve olympique ; synchroniser transactions et communication inter-nœuds recèle plus d’embûches que le parcours client moyen chez certains opérateurs télécoms.
Les avantages et inconvénients de chaque approche : une affaire de compromis, comme toujours.
Comparer vertical versus horizontal revient à choisir entre escalader un gratte-ciel tout droit ou gravir une montagne par sentiers multiples. Aucun modèle n’a le monopole du bon sens : tout dépend du contexte réel — ambitions techniques, budget disponible, tolérance au risque... Il serait infantile (mais fréquent dans les comités stratégiques) d’opposer dogmatiquement l’un à l’autre sans nuance ni vision sur-mesure.
| Critère | Scalabilité Verticale | Scalabilité Horizontale |
|---|---|---|
| Coût initial | Modéré jusqu’à un certain niveau | Plutôt élevé (plusieurs machines) |
| Coût long terme | Peut devenir prohibitif | Potentiellement inférieur |
| Complexité gestion | Faible | Élevée (gestion cluster/distribué) |
| Résilience/pannes | Faible (point unique de défaillance) | Forte (redondance naturelle) |
| Performance max | Limitée par matériel | Très élevée mais dépend architecture |
| Flexibilité évolutive | Très faible après seuil matériel | Excellente selon besoins réels |
On ne s’y trompe pas : rester sur du vertical trop longtemps expose à l’obsolescence technique ou à la panne fatale là où l’horizontal permet une croissance quasi illimitée… au prix d’un effort organisationnel et intellectuel conséquent (que beaucoup sous-estiment allègrement).
Le choix stratégique : quand faut-il opter pour l'une ou l'autre, ou une combinaison savante ?
Soyons honnêtes : ceux qui prônent un modèle unique font rarement preuve d’expérience terrain. Un choix avisé doit prendre en compte non seulement les contraintes financières immédiates mais aussi la trajectoire probable du projet. Pour un MVP pressé ? Optez sans complexe pour le vertical – c’est rapide et peu risqué, tant que vous savez que cette béquille ne tiendra pas longtemps face au succès. Pour les plateformes ambitieuses visant volume massif ET disponibilité maximale ? Il faudra tôt ou tard migrer vers un modèle horizontal — quitte à souffrir lors du passage.
Dans bien des cas réellement modernes, l’intelligence consiste avant tout à hybrider les deux stratégies : monter progressivement en vertical jusqu’au plafond acceptable puis amorcer bascule vers horizontalité lorsque les limites matérielles sont atteintes (preuve ici). Certains services cloud permettent désormais cette transition quasiment "à chaud", mais croire qu’elle se fait sans douleur est une douce illusion…
Anecdote piquante : chez un éditeur SaaS réputé chic mais fauché, le refus obstiné de passer du scale up au scale out a mené droit dans le mur lors du premier salon professionnel – crash généralisé après 2000 visiteurs connectés simultanément… Il leur aura fallu trois mois et autant d’ingénieurs brûlés pour sortir enfin du verticalisme béat. Moralité ? La scalabilité ne pardonne jamais l’approximation ni l’égo technocratique.
Les pièges de la scalabilité : les fausses promesses et les goulots d'étranglement inattendus
Confondre croissance et scalabilité : le raccourci qui coûte cher
Avouez-le, on a tous été tentés par cette simplification : croire qu’augmenter le volume d’utilisateurs ou la puissance de calcul revient à "scaler". Pourtant, cette confusion entre croissance brute et scalabilité maîtrisée est l’une des erreurs les plus flagrantes du secteur. On se rassure avec quelques courbes ascendantes dans Power BI, puis on réalise – trop tard – que la simple croissance dégrade l’efficacité du système, au lieu de l’améliorer.
Les discussions sur LinkedIn et dans maints comités stratégiques s’enlisent encore dans ce mirage : "Plus d’abonnés, donc nous sommes scalable". Non ! La vraie scalabilité implique une capacité à absorber cette croissance sans faire exploser les coûts ni effondrer la qualité de service (source).
Conséquences courantes de la confusion croissance vs scalabilité :
- Explosion des coûts opérationnels (plus de serveurs… mais aussi plus d’ingénieurs à réveiller la nuit !) ;
- Dégradation progressive des performances (lenteur, bugs intermittents) ;
- Instabilité chronique : chaque pic de charge devient une loterie pour la survie du service ;
- Perte de clients et détérioration irréversible de réputation ;
- Architecture incapable d’anticiper et d’accompagner l’évolution réelle des besoins.
Résumons : le jargon sur la scalabilité masque surtout une gestion très terre-à-terre des ressources humaines, matérielles et budgétaires, bien loin des envolées lyriques sur l’innovation perpétuelle.
Le coût caché de l’élasticité : complexité technique ET humaine en embuscade
Si l’élasticité (notamment via le cloud) fait rêver les DSI en mal d’agilité, elle génère en réalité une complexité exponentielle. Multiplier les serveurs ne résout rien si vous ne maîtrisez pas orchestration, monitoring avancé, gestion fine des ressources… Et il n’existe pas encore d’outil magique qui synchronise instantanément vos données sans latence ni bug fantôme (source).
Cette flexibilité technique impose aussi un niveau d’exigence accru au niveau humain :
- Surveillance continue obligatoire (les incidents se multiplient proportionnellement aux points potentiels de défaillance !)
- Nécessité de compétences rares en administration distribuée ;
- Problèmes organisationnels (silos techniques, coordination inefficace entre équipes…)
- Maintenance qui vire rapidement cauchemar si le design initial était bâclé.
Rien n’est plus révélateur que ces nuits blanches passées à "débroussailler" un cluster incohérent… Anecdote vécue : chez un éditeur SaaS pressé d’épater la galerie avec son cloud auto-scalable, il aura fallu quatre mois pour comprendre que le vrai goulet était RH : aucune compétence réelle en scripting distribué dans l’équipe… tout simplement !
Les goulots d’étranglement : quand le scalable s’étouffe tout seul
On pourrait croire – naïveté oblige – que disperser charge et stockage suffit à garantir la montée en charge. Or, les architectures dites scalables sont souvent entravées par des goulots d’étranglement criants :
- Bases de données centrales saturées sous requêtes concurrentes ;
- Réseaux internes limités par le débit ou la latence ;
- Mauvaise communication inter-services (APIs lentes ou mal conçues).
Le débat est régulièrement relancé sur Slashdot ou dans les communautés DevOps : comment identifier ces points faibles avant qu’ils ne paralysent tout ? La solution tient moins dans un outil miracle que dans un audit régulier méticuleux (tests de charge ciblés), une analyse proactive du code source et une capacité à refactoriser sans pitié dès qu’un nouveau goulot apparaît (source).
La gestion des données : partitionnement, cohérence et autres casse-têtes distribués
Quand il s’agit de scaler côté données, c’est là que commence vraiment la douleur. Le partitionnement (sharding) promet monts et merveilles : distribuer une base sur plusieurs serveurs pour gérer plus d’utilisateurs. Mais chaque découpage induit un enfer logistique dès qu’il faut agréger ou synchroniser ces fragments — sans garantie totale que la cohérence sera préservée (voir ici).
On distingue alors deux mondes :
- Cohérence forte : chaque transaction voit toutes les données comme à jour partout… mais au prix d’une latence accrue (!)
- Cohérence faible : acceptation temporaire d’informations divergentes entre nœuds pour gagner en rapidité — impensable pour les transactions financières critiques mais toléré pour du réseau social.
Résultat ? Les compromis sont inévitables entre performance brute, simplicité architecturale et exigences métier. Soyons lucides : aucun choix n’est indolore.
Microservices : solution miracle ou boîte de Pandore ?
L’architecture microservices est aujourd’hui brandie comme LE ticket gagnant vers la scalabilité ultime (source). D’accord, chaque composant peut évoluer indépendamment… En théorie seulement.
Dans la pratique :
- Coordination inter-services chronophage,
- Multiplication des points de défaillance,
- Surveillance démultipliée,
- Complexité organisationnelle qui explose dès dix microservices distincts.
Certains géants comme Airbnb ont appris à leurs dépens que migrer vers ce modèle pouvait générer un tel enchevêtrement technique que même corriger un bug anodin virait au parcours du combattant (preuve). Encore faut-il disposer d’équipes formées aux concepts distribués ET capables de maintenir la cohésion globale sans sombrer dans le chaos documentaire ni multiplier bugs interstitiels.
En synthèse : le microservice n’est ni panacée ni diable absolu. Il impose juste ce dont peu veulent parler — discipline méthodologique permanente, rigueur documentaire extrême et humilité devant l’impossibilité pratique de tout anticiper.
Atteindre la scalabilité : une roadmap réaliste, loin des discours marketing
Anticiper les besoins : deviner le futur, ou du moins, essayer
On aimerait croire qu’il suffit de suivre un guide étape par étape pour obtenir une architecture scalable. Malheureusement — et sans vouloir froisser les vendeurs de recettes miracles — la réalité est autrement plus cruelle : la scalabilité ne s’improvise pas. Les systèmes « faits pour durer » sont presque systématiquement ceux qui ont été pensés avec une capacité d’évolution dès la genèse. Construire aujourd’hui sans imaginer la croissance (ou, soyons honnêtes, l’effondrement possible) de demain revient à ériger une cathédrale sur du sable mouvant.

« Rien n’est plus coûteux qu’une architecture rigide incapable d’accompagner l’évolution des usages. »
L’anticipation sérieuse exige un diagnostic impitoyable des besoins réels et potentiels : charge attendue, pics saisonniers, diversification fonctionnelle… Ceux qui sous-estiment ce travail préliminaire se condamnent à des refontes ruineuses ou à l’obsolescence prématurée (un nombre affligeant de plateformes dites “innovantes” ont tout simplement implosé faute d’anticipation).
La règle ? Prévoir large, mais concevoir modulaire. Les composants doivent pouvoir être ajoutés, remplacés ou supprimés sans provoquer d’effet domino ni crise existentielle au sein des équipes SI. Oublier ce principe relève soit de la paresse intellectuelle soit d’un optimisme dont on connaît l’issue en production.
Concevoir pour évoluer : dès le départ, penser au-delà du présent
L’idée paraît triviale mais reste minoritaire dans les faits : chaque brique technologique doit être pensée comme temporairement définitive — susceptible d’être remplacée sans créer un séisme. La modularité, le découplage fort entre services et la documentation impeccable sont autant de garde-fous contre l’effet tunnel fatal quand vient le temps de scaler vraiment (ou de pivoter en urgence). Un système bâti dans cette optique tolérera bien mieux l’ajout inattendu de fonctionnalités ou la migration vers de nouvelles infrastructures.
Mesurer et optimiser : surveiller les performances comme le lait sur le feu
Le mythe du « ça marche donc c’est bon » a fait son temps. Une architecture scalable impose une mesure continue — non pas pour rassurer un comité stérile mais pour identifier précocement les signes précurseurs de saturation ou d’instabilité.
Les outils modernes (métriques fines sur temps de réponse, taux d’erreur applicative, utilisation CPU/Mémoire/Disque réseau…) sont indispensables mais insuffisants sans une lecture experte des résultats et un plan réactif permanent.
Actions concrètes pour surveiller et optimiser la scalabilité :
- Mettre en place un monitoring centralisé (Prometheus, Datadog…) avec dashboards personnalisés ;
- Collecter et analyser logs applicatifs/infra en temps réel pour détecter patterns anormaux ;
- Définir des alertes proactives sur seuils critiques (latence utilisateur > X ms, CPU > 85%) ;
- Programmer des audits réguliers du code et de l’infrastructure ;
- Réviser périodiquement les capacités allouées versus besoins réels ;
- Impliquer systématiquement les équipes SI dans l’analyse continue et le plan d’action correctif.
Nier cette dynamique revient à piloter avec des œillères : chaque incident deviendra alors une surprise… ponctuée d’appels nocturnes inutiles aux équipes déjà épuisées.
Tester, tester, encore tester : simuler la montée en charge avant qu'elle ne devienne une réalité
Tout système censé résister à la montée en charge doit prouver sa valeur AVANT que celle-ci survienne effectivement ! Les tests de charge ne sont pas un supplément décoratif mais bien le cœur du dispositif anti-catastrophe : ils révèlent les goulots cachés que même les plus brillants architectes oublient sous pression commerciale.
Des outils spécialisés permettent aujourd’hui de simuler différents scénarios – montée progressive jusqu’au crash contrôlé inclus – mais peu osent aller assez loin dans l’exercice. Résultat ? C’est toujours lors des événements “hors norme” que tombent masques et promesses creuses.
Un conseil cruel mais sincère : testez jusqu’à l’absurde, car c’est là que surgissent les vrais défauts structurels. On se souvient encore du lancement raté d’une application bancaire réputée “prête pour le million”, effondrée dès 45 000 connexions simultanées…
Choisir les bons outils et technologies : sélectionner ses alliés pour la bataille
Adopter les bons outils techniques n’a rien d’un luxe superflu face à la complexité croissante.
- Les architectures microservices (autopsie indispensable ici : Les architectures microservices - avantages et inconvénients) permettent d’isoler chaque fonction critique pour monter en charge indépendamment ;
- Les bases NoSQL type Cassandra/MongoDB s’imposent si vous visez volume et rapidité horizontale ;
- Le cloud computing (AWS/GCP/Azure) autorise une flexibilité quasi instantanée dans l’allocation/désallocation ressources ;
- Les caches distribués type Redis/Memcached absorbent paliers critiques sans grever la base principale.
Mais — point capital trop souvent ignoré — ces technologies exigent une expertise humaine rare : rien n’est plus dangereux qu’un outil mal maîtrisé par des équipes sous-formées… On voit encore trop souvent “l’usine à gaz” auto-infligée détrôner tous bénéfices attendus.
L'agilité organisationnelle : adapter sa structure aux exigences de la scalabilité
Il serait naïf (voire irresponsable) de croire que la scalabilité se décrète uniquement côté IT ! La réussite dépend aussi cruellement de l’agilité organisationnelle : capacité à faire évoluer process internes, communication transversale efficace et formation continue des équipes opérationnelles comme techniques.
Les structures figées minent toute tentative sérieuse d’adaptation à grande échelle. Cultiver apprentissage permanent et flexibilités hiérarchiques devient vital — non seulement pour tenir face aux imprévus mais aussi anticiper ce que même vos outils analytics ne sauront jamais prédire. Là où certains rêvent encore d’automatisation toute-puissante, il faudra surtout compter sur intelligence collective ET humilité partagée devant la complexité croissante.
On ne s’y trompe pas : négliger l’humain expose au syndrome classique du “tout marchait parfaitement jusqu’à ce que…” – phrase entendue mille fois lors des audits post-mortem dans les projets avortés.
La scalabilité dans la vraie vie : exemples concrets et applications variées
Les géants du web : Facebook, Google et Amazon, ou l’art de domestiquer la démesure
Disons-le sans trembler : la plupart des entreprises n’auront jamais à encaisser le dixième d’un Black Friday chez Amazon ou d’un live-stream massif sur YouTube, et c’est tant mieux pour leur santé mentale. Pourtant, il faut observer comment ces mastodontes gèrent leurs infrastructures pour comprendre ce qu’implique réellement la scalabilité à l’échelle industrielle.
Amazon s’est construit autour de backends "heavy scalable", capables d’orchestrer des flottes de serveurs répartis sur des continents entiers (High Scalability). Côté Google, ce sont les fameux datacenters hyperscale, la gestion algorithmique du traffic mondial et une architecture orientée microservices — chaque brique peut être remplacée à chaud en cas de panne. Quant à Facebook/Meta, on parle de systèmes capables d’avaler des milliards de requêtes par jour, soutenus par des bases de données maison (Cassandra, RocksDB) pensées pour la réplication planétaire.
Soyons lucides : tout cela repose sur des principes rarement transposés dans les PME — partitionnement massif des données (sharding), automatisation totale de la supervision, tests continus en production (parfois au prix d’incidents mémorables…). Tout est conçu pour casser l’ancien paradigme du "gros serveur central" au profit d’un essaim dynamique où chaque panne doit être vue comme banale plutôt que cataclysmique.
Résumé des stratégies phares :
- Découpage extrême en microservices autonomes ;
- Stockage distribué et redondant sur plusieurs zones géographiques ;
- Orchestration automatique du provisioning et de la montée/descente en charge ;
- Tests en conditions réelles, y compris injection volontaire de pannes (GameDays chez Amazon).
« La scalabilité chez les géants n’est pas une option mais l’unique façon d’exister face à des volumes inhumains. Ceux qui s’en inspirent doivent surtout retenir le sens aigu du pilotage par les faits – pas par slogans.»
Startups disruptives : le passage express du garage au million d’utilisateurs — ou presque
Contrairement aux idées reçues, la réussite fulgurante d’une startup ne tient pas seulement au génie marketing mais souvent à la capacité technique de scaler sans imploser (Blast Club). Netflix est un exemple canonique : passé du DVD expédié par poste à un moteur mondial de streaming via une migration méthodique vers le cloud AWS — chaque palier franchi a imposé refonte après refonte.
D’autres plateformes comme Spotify, Slack ou Zoom n’ont survécu qu’en industrialisant dès leurs premiers mois automatisation, standardisation technologique et monitoring. Le secteur du streaming n’a rien d’une promenade : chaque nouvelle acquisition d’utilisateurs peut faire basculer toute l’architecture dans le chaos si elle n’a pas été pensée modulaire et élastique dès le début.
Les startups qui échouent ? Celles qui confondent levée de fonds avec capacité réelle à absorber dix mille nouveaux utilisateurs en une nuit… La différence se fait dans la discipline technique plus que dans les pitchs flamboyants.
Systèmes critiques : banque, santé – question de vie ou de mort technologique
Dans une banque ou un hôpital moderne, il ne s’agit plus seulement « d’encaisser plus » mais d’assurer une disponibilité absolue sous contrainte réglementaire sévère (Kaliop). Un système bancaire incapable de scaler lors du paiement des salaires ? C’est une crise nationale. Un dossier patient indisponible parce qu’une infrastructure santé n’a pas anticipé sa montée en charge ? On frise l’inconscience professionnelle – voire pénale.
Dans ces secteurs ultra-sensibles, la moindre latence excessive ou coupure discrédite tout l’écosystème. D’où l’empilement méthodique : architecture multi-sites actifs/passifs redondants, synchronisation temps réel entre bases distribuées et audits permanents de conformité… Un cauchemar organisationnel pour beaucoup mais un standard vital ici. Soyons honnêtes : seule la paranoïa systématique permet à ces structures critiques d’éviter désastres majeurs.
Cloud computing : accélérateur ou mirage moderne ?
Les fournisseurs cloud (AWS, Azure, GCP) vendent aujourd’hui le rêve industriel d’une scalabilité quasi illimitée – verticalement ET horizontalement (Gigamon Blog). Plus besoin « d’acheter vos propres racks » : on provisionne CPU/RAM/Bandwidth à la demande, on scale up/down selon les pics réels… Ou presque !
Ce modèle repose sur deux vertus cardinales :
- Facturation à l’usage (évite le gâchis structurel)
- Allocation dynamique automatisée via API (auto-scaling groups)
Mais avouez-le : cette simplicité cache mal la nécessité impérative d’une conception logicielle adaptée au cloud natif — stateless by design, découplage fort des services et maîtrise des coûts cachés liés au storage/distribution massif.
Un retour terrain peu glorieux ? Tant que l’équipe ne maîtrise pas vraiment son stack cloud ET ses processus DevOps associés… Le budget peut exploser aussi vite que la charge utilisateur !

Au-delà du SI : modèles économiques et organisations scalables – le vrai tabou français ?
Réduire la scalabilité aux seules machines est naïf : le concept irrigue aussi modèles économiques et structurations internes (Ecommerce Nation). Dans un business model scalable – pensez SaaS ou marketplace –, chaque nouvel utilisateur génère un revenu supplémentaire sans imposer coûts fixes proportionnels. Ici réside LA différence avec les modèles artisanaux où toute croissance se paye cash par davantage d’embauches/matériel/processus inutiles.
CCM Benchmark Group ou autres acteurs pureplayers digitaux ont bâti leur rentabilité sur cette loi implacable : industrialiser chaque maillon du service pour supporter 10 puis 100 fois plus sans explosion RH ni TMA insoutenable. L’automatisation commerciale/facturation/support devient alors LE nerf vital — autant que celles côté serveurs !
Les entreprises traditionnelles réticentes paient aujourd’hui leur retard : incapacité chronique à pivoter leur organisation pour encaisser vraiment la réussite espérée… même lorsque (miracle rarissime) celle-ci finit par vouloir arriver.
En synthèse : La scalabilité vécue n’a rien du conte LinkedIn ; elle suppose discipline technique extrême ET transformation organisationnelle profonde – deux horizons où bien peu tiennent honnêtement leurs promesses.
La scalabilité : une quête permanente
Sans vouloir jouer les rabat-joie, il est temps de refermer cette fresque sur la scalabilité en martelant ce que trop d’experts autoproclamés préfèrent ignorer : la scalabilité n’est jamais acquise, elle se (re)construit chaque jour. Ceux qui la présentent comme un point d’arrivée, gravé dans le marbre d’une roadmap ou d’un audit PowerPoint, manquent soit de lucidité, soit de scrupules — ou les deux.
On l’aura compris : il ne suffit pas de croître pour scaler — ni d’empiler jargon et frameworks tendance pour garantir agilité et résilience. Le véritable enjeu se niche dans ce va-et-vient perpétuel entre anticipation pragmatique, adaptation continue et acceptation (souvent douloureuse) des compromis techniques et humains. Avouez-le : chaque avancée majeure dévoile de nouveaux goulets d’étranglement, chaque « victoire » tech n’est qu’un sursis… jusqu’au prochain défi.
Gardons-le en mémoire : la scalabilité est un mouvement, pas une statue. Refuser la remise en question régulière, céder à la facilité du marketing auto-satisfait ou croire au miracle des architectures prétendument auto-suffisantes condamne immanquablement à la stagnation — voire au crash retentissant. À l’heure où tout change plus vite que nos process internes, mieux vaut cultiver le doute méthodique et l’humilité technique que s’endormir sur des slogans creux.



